
Ollama is a versatile tool that I’ve been using for several months to handle various tasks. It's easy to install and easy to use. Initially, I applied it to smaller projects, but recently, I’ve been leveraging it for more complex tasks that involve larger amounts of content.
One of my primary use cases involves taking receipts, performing Optical Character Recognition (OCR) on them, and then using a large language model (LLM) to extract essential information such as the date of purchase, vendor, category, and amount. Using Ollama with LLAMA3.1:8b has been a great experience most of the time. However, I’ve encountered challenges with certain receipts that contain extensive content beyond the actual receipt details.
For example, consider a PDF receipt from a mobile phone provider. It might include one or two pages with purchase information and then 20 pages of phone log details. In such cases, the context window becomes a significant limitation. Although LLAMA3.1 supports up to 128K tokens for context—a substantial capacity—I’m only able to utilize about 8K tokens by default when running:
ollama run llama3.1:8bThis discrepancy means that the LLM often cannot process the full document context, causing the initial instructions for data extraction to be lost. As a result, the consistency of the extraction results varies based on the document size. While small documents yield accurate results, larger ones may lead to inaccurate or incomplete data extraction.
To make matters worse, the OpenAI API integration with Ollama doesn’t currently offer a way to modify the context window. This limitation restricts flexibility and exacerbates the inconsistency in results across different document sizes.
Addressing this challenge is crucial for maintaining the reliability of data extraction processes, especially as I scale up to handle more extensive documents. Potential solutions could involve optimizing the preprocessing steps to minimize irrelevant content or exploring alternative models with more adaptable context windows.
Solution
We need to modify the default context window! Let's create a new Modelfile that we're going to use and this will be used to extend our context window.
# Modelfile
FROM llama3.1:8b
PARAMETER num_ctx 32768This is a very simple file, but let's go over it. The FROM is saying what model we're going to be using. In my example, I am using llama3.1:8b so I'm going to keep this the exact same. I then provide a PARAMETER who's key is num_ctx and the value is 32768. This will give us a context window that is 4x larger than the default one.
We can now "apply" this to our existing model.
ollama create -f Modelfile llama3.1:8bSo, before, we had 8192 context size.
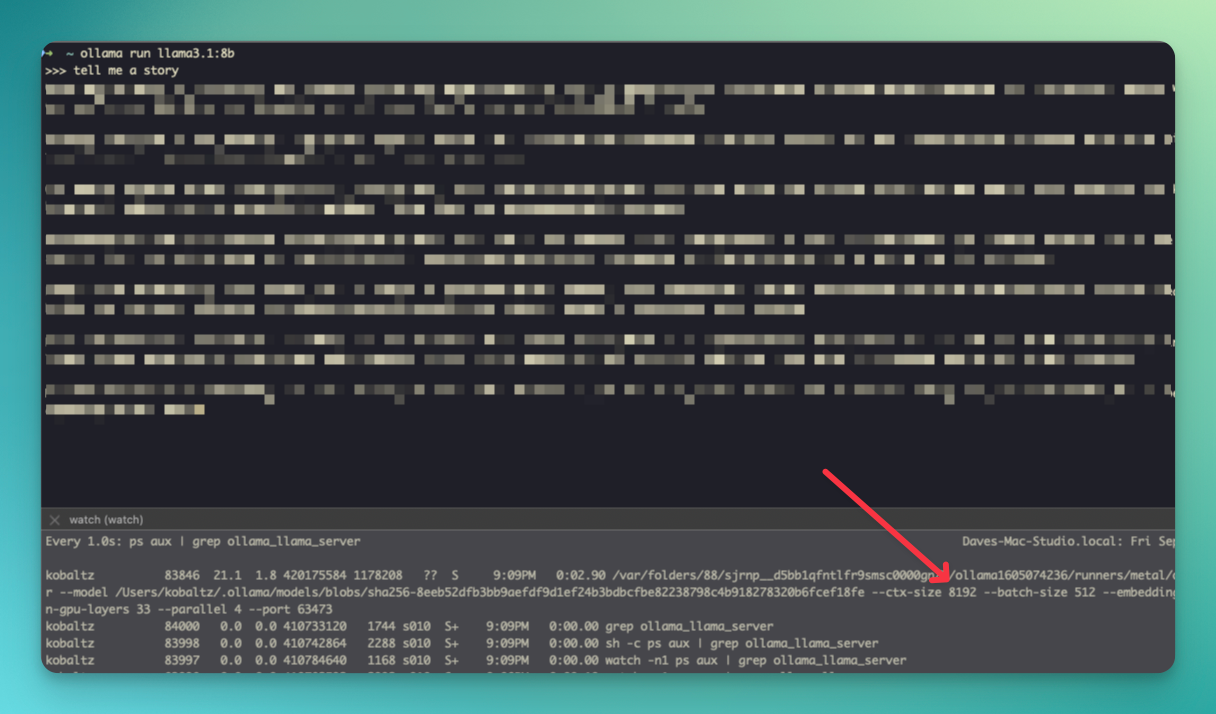
Now, the context window size is showing a much larger size. I've tested this out in reading large amounts of data and it was able to keep up with the context without losing information. Of course, if you had really large files, then you would be hitting the context limits again.
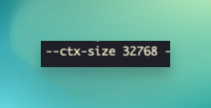
If you need an even larger context window, you can increase this to 131072 which is the 128k context limit that llama3.1 has.
There's also something else important to know. In increasing the context window, I also increased the amount of VRAM that was being used. I don't have exact numbers, but for most practical purposes, I found 32768 to be sufficiently fast, low on VRAM and would fit the largest contexts that I needed.

Member discussion: