I created a Github Issue on the Kamal Repo for visibility as this problem wasn't clear. There were definitely hints as to what the problem was, but it wasn't a straight forward solution. Well, actually, in hindsight, it did seem pretty logical. However, at the time when you're getting that scary image on your screen when you refresh for the first time after an upgrade.

Panic can set in and logical thinking can go right out the window.
Upgrade Process
My upgrade process for Kamal was fairly simple. I tested it out on a local environment to make sure that I understood the new config options and then tried deploying Kamal 2.0 on Drifting Ruby.
There is a neat feature that I either didn't realize existed or is new. You can run kamal config locally to see if your config will have the potential to deploy successfully. Basically, it just verifies that there aren't issues within the config.
With the introduction of Kamal 2.0, we are no longer using the traefik proxy and instead now using kamal-proxy. The upgrade process is fairly simple, but does require changing a few things. Once you upgrade Kamal to version 2.0... wait! Before you do this!, you should upgrade to version 1.9.0 because this version offers a "downgrade" feature that will remove kamal-proxy and replace it back with traefik. This can be critical if you're in a situation where you need to go backwards and get the site back up and running while you troubleshoot an issue. I know, because I ended up having to do this.
But, assuming that you've successfully deployed 1.9.0 and you're now upgrading to 2.0.0, the first thing that you'll need to do after updating and installing the gem is to run
kamal initThis will create a new file .kamal/secrets which is meant to replace the .env file. This file will be committed to your version control, so do not put your actual secrets in there. Luckily, the generated file provides a few different examples that you can use in order to find what will work best for you. In my case, since all of my apps using Kamal to deploy share the same Docker Hub account, I have this within the secrets file.
# Option 1: Read secrets from the environment
KAMAL_REGISTRY_PASSWORD=$KAMAL_REGISTRY_PASSWORD
# Option 2: Read secrets via a command
RAILS_MASTER_KEY=$(cat config/credentials/production.key)While using Rails Credentials does have some drawbacks like rotating keys can be a bit annoying or your key gets compromised and now every secret needs to be rolled and an audit done to see if there was any breaches, it does make it a lot easier to manage from an infrastructure standpoint.
Then we need to update the config/deploy.yml file. I removed the references to the traefik as that was no longer needed. In my initial discovery on my test app, I saw that the application deployed successfully, but I was unable to access the website. This is because the kamal-proxy assumes that the application's port is 80 instead of 3000. This was the biggest change that I had to made to the deploy.yml file outside of cleaning up the no longer used things. But remember that kamal config will let you know if you have some lingering obsolete configs. To tell kamal-proxy that you need to use port 3000 instead, you'd insert a new key for the proxy and then use app_port to specify the port.
proxy:
app_port: 3000Once this is all done, you can begin your upgrade with
kamal upgradeThis will ask you to confirm that you'll be deleting the traefik proxy and use kamal-proxy instead. Once this upgrade happens, you should be good to go. However, if you're like me and it didn't go smoothly, keep reading on.
Enter AWS ALB Load Balancer
I would like to think that my infrastructure if fairly simple. In its most simple terms, this is what the infrastructure looks like.
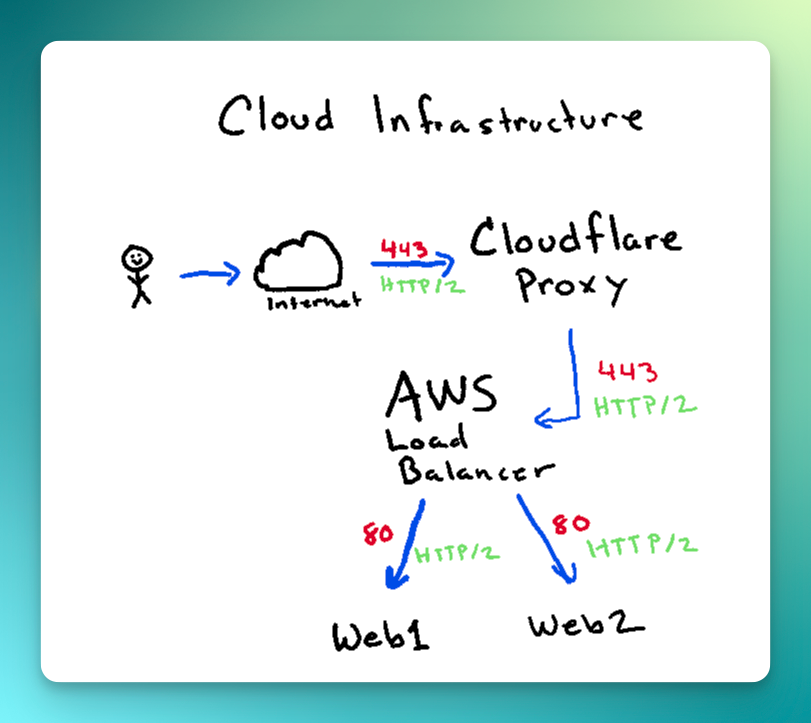
When deploying with Kamal 2.0, there didn't seem to be any issues. It successfully deployed and I thought that everything was good. However, that's when the dreadful Cloudflare error page showed up and I paniced.
I immediately looked at the documentation and my test app's config to see if there were any things that I may have missed, but everything looked fine. Since I knew what my infrastructure looked like on the test application, it helped me narrow some things down. The big differences between the test application and Drifting Ruby's infrastructure is the AWS Load Balancer and an additional Web Server. Since the web servers were on separate hosts, I didn't think that would matter. So I looked in the logs with kamal app logs -f and that's when the problems started to become a bit more clear. Well, not really because I had no idea what it mean. In my error logs I saw the repeated message Unsupported HTTP Method used: PRI which seemed odd.
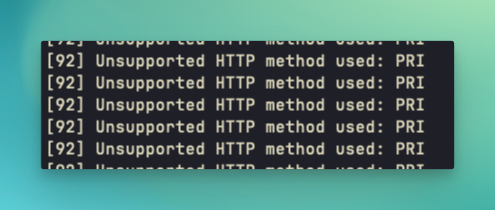
Searching around for that error message returned multiple sites pointing to it being an HTTP/2 problem. I knew that I was using HTTP/2 on my test application through the Cloudflare Proxy, but the only difference in this case that was applicable was the AWS Load Balancer. So, I looked on there and saw that I had configured the Target Group for the load balancer to use HTTP/2 as well. This really shouldn't matter since Cloudflare is doing the initial handshake with the browser and setting the protocol that will be used on the page.
Sadly, AWS doesn't just let you change the Protocol version either. I had to create a new Target Group (mimicking the settings from my original Target Group) but use HTTP 1instead.
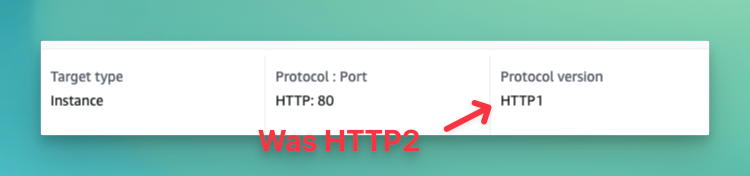
After this change, the site immediately came back up and everything was good. Since then, I've tried deploying again and it went without any issues.
I hope that this helps you if you've run into this issue too!

Member discussion: