
Remember those "Choose Your Own Adventure" books? I loved those as a kid. For those who don't know what they are, they're adventure books that are not meant to be read from front to back. Instead, you read a page or two and then you're left with a few choices. Depending on which option you choose, you can flip to a specific page to continue the story.
Using various LLMs, I was able to dynamically generate my own! The process is fairly simple where you pick the kind of text you want to have generated. Then, background jobs will be kicked off and the content will be generated.
Here's a basic overview of how something like this happens.
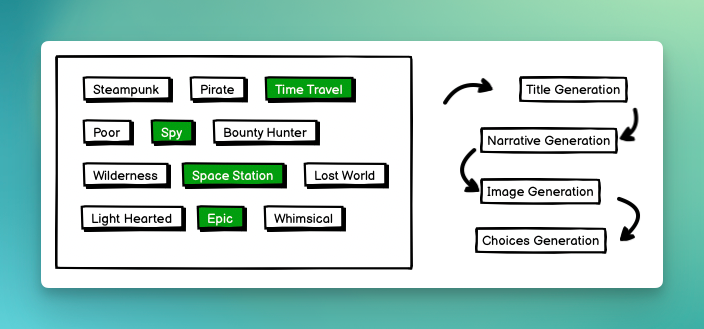
Prompt Chaining
But it's actually not so simple. The Title Generation is created off of the various prompts that the user initially selected. Then the Narrative Generation will start creating the text for the story. This is a fairly creative step for the LLM and is given a lot of room to do its thing.
However, the Image Generation step isn't so simple. You cannot simply give the Narrative to the Image Generator and expect good results. Instead, you need to have a prompt for this LLM to generate a somewhat related image. So, Another call to the generative text LLM is made where it feeds in the narrative and is expecting a prompt response that is formatted for Stable Diffusion.
The choices option is also very similar where based on the narrative, a few different options are given. The general nature of generative text LLMs is that they are very bad at following instructions. This is especially true with smaller models. In all of the text generations on this project, I'm using an 8b parameter model. That's super small! The generative text is often chatty and not in a format that can easily be parsed by Ruby. So, instead of trying to design the "perfect" prompt that would work, I make two separate requests. The first request is more on the creative side. I feed in the narrative and with a temperature of 0.7 I ask for a list of options. I then make another request feeding in the response from the previous one and ask the LLM to format this in an array. Since its context is so small, just my request prompt plus the context of the "actions", it's able to handle this fairly well.
By having multiple prompts and chaining the responses, I'm able to consistently get better results even from a small LLM. Not only this, but it's a bit more universal in being able to switch models. If I want to test out a different small model, I can and most often the Choices Generation will still work.
Application/Technology Used
This application is a very vanilla Rails 8 application. I added one gem into the Gemfile that's outside of the provided defaults. There's only two controllers since most of the work happens in the background jobs. Since this is a fresh Rails 8 application, SolidQueue is being used for the background worker and SQLite is being used on the database side. Kamal is being used to deploy this to a VM that I'm self-hosting.
That's basically it. The entire application is under 1000 lines of code. It's missing a lot of features like authentication and authorization. It's also missing some potentially cool features like Inventory tracking, but for a "MVP", I was fairly happy with the results.
The code is also very simple. The most complicated part of the code is creating the HEREDOC for the prompts. There's several prompts that go into this as we've already talked about. The other bits of the code is fairly simple as well. I'm using the ruby-openai gem to communicate with the LLMs. I'm hosting these locally
def generate
client.chat(
parameters: {
model: Rails.configuration.default_model,
messages: [ { role: "user", content: @prompt } ],
temperature: @temperature,
stream: stream_proc(self)
}
)
end
private
def client
@client ||= OpenAI::Client.new(
access_token: Rails.configuration.default_ollama_token,
uri_base: Rails.configuration.default_ollama,
)
endThe real-time streaming of the prompt happens from the stream option that's passed into the generation. It's actually quite simple where we basically take and update the existing narrative with the chunked content. This does create a burst of writes to the database, but it's also the most simple and direct approach. If I had to scale this, I would probably do something a bit different where I simply broadcast appending the new content and store everything in an array. Once the stream is finished then I could update the database with the final results.
def stream_proc(message)
proc do |chunk, _bytesize|
new_content = chunk.dig("choices", 0, "delta", "content")
@scenario.update!(narrative: @scenario.narrative.to_s + new_content.to_s)
end
endThe broadcasting, or live updates, is simply handled by ActionCable and turbo streams. No Javascript necessary. Since this is just a hobby project and the most life it'll see is the short days of this post coming out, I'm not too worried about performance. But I would basically have this broadcast function in the model as is, but have another broadcast in the stream_proc. However, this also has some potentials of things getting out of sync. Because, if the jobs are processed out of order (which is very likely to happen), then it will essentially cause text to be inserted out of order. You could get around this by broadcasting the whole array joined together as a string and that would have a much better chance of staying together.
after_save_commit {
broadcast_replace_to(
adventure,
target: "scenario_adventure_#{adventure.id}",
partial: "adventures/scenario",
locals: { scenario: self }
)
}
Hardware/GPUs
I am using a fairly massive GPU for this task, but it's really not required. A smaller and significantly less expensive GPU with 16GB of VRAM could do this job all the same. There's also a lot of options out there if you want to use metered-based APIs or other options. I won't recommend any right now, because I typically run all of my LLMs in house.
But, if you're able to get your hands on a RTX 4060 Ti 16GB, you can run quite a bit with the 16GB of VRAM. There's also the RTX 5070 Ti which is being released on Feb 20th, 2025 (tomorrow as of the time of this writing), but the demand for these cards will be high. I'm a big fan of the consumer cards since I'm able to run what I need on them and I'm not doing anything critical.
There's a lot of misconception about the GPUs and what's required with them. In short, if you're running Inference (text generation, image generation, voice generation) then you do not need an insanely fast GPU or GPU PCIe lane bandwidth. Once the model is loaded into video memory, it is the bandwidth between the video memory and the graphics processor that will make the biggest difference. All of this meaning... you can use a PCIe 4.0 slot in 4x mode and still be okay. You won't be running into bottlenecks due to the PCIe lane bandwidth. This is a completely different story if you are fine tuning or training your own model. There is much more exchange that goes on between the GPU and the CPU, so running the full 16x lane becomes much more important.
Wrap up
Here's the link to the Choose Your Own Path if you want to play around with it. Keep in mind that I am hosting this on my local network and using my GPUs for the inference and image generation, so be kind. I likely won't keep this project online indefinitely so tinker around with it while you can!
Choose Your Own Path -> https://cyop.railsapp.dev

Member discussion: